
Livre étudiant – Réseaux informatiques : analyse du chargement d’une page web
Séance 1 : analyse du chargement d’une page Web
Exercice 1 : Introduction
L’objectif de cette première séance est de produire des graphes qui décrivent les caractéristiques des échanges effectués lors du chargement d’une page Web : nombre de serveurs contactés, localisation et entreprise propriétaire de ces serveurs, ou encore volumes données transférées. La Figure 1 présente un exemple des résultats que nous souhaitons générer.
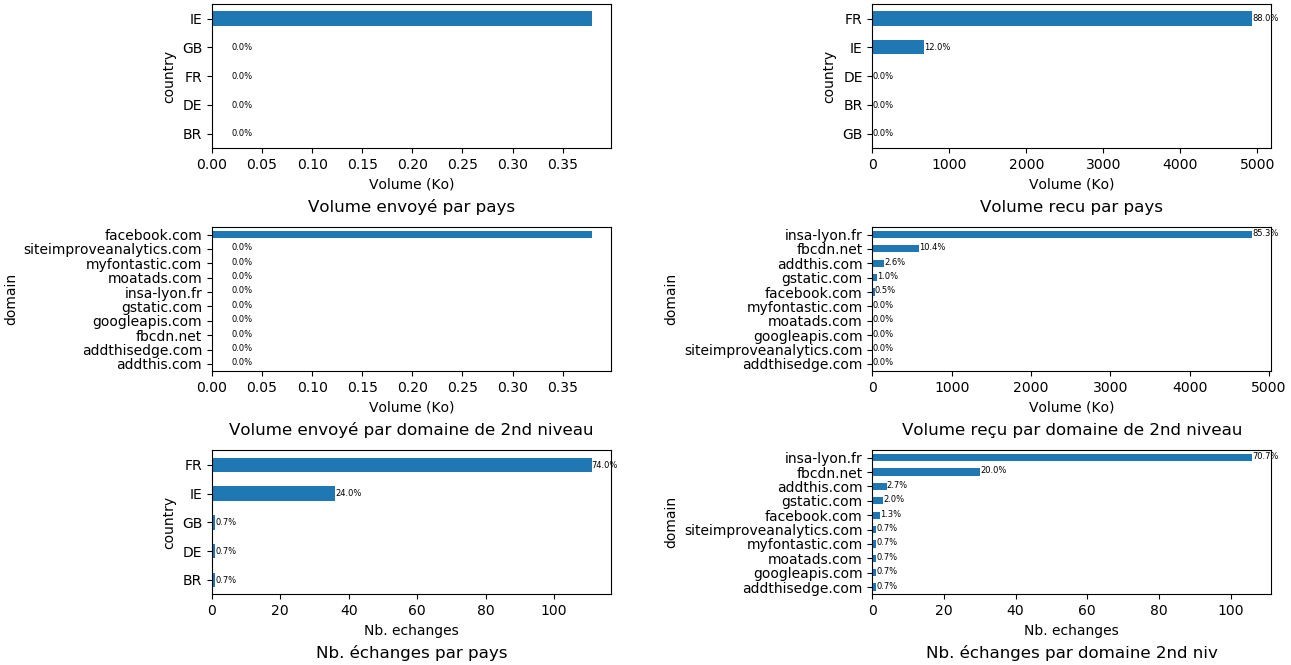
Figure 1 – Exemple de résultats issus de l’analyse d’un fichier HAR.
Pour produire ces résultats, nous allons procéder en plusieurs étapes consécutives :
- chargement d’une page Web dans un navigateur
- récupération d’un journal d’évènement réseau HAR
- analyse du journal par un script Python afin de produire des résultats synthétiques
1.1. Chargement d'une page web

Figure 2 – Analyse du chargement d’une page Web à travers différentes étapes.
1.2. Journal HAR
Un journal HAR (pour HTTP Archive) est habituellement stocké dans un fichier avec .har et contient des données sur le chargement d’une page Web dans un navigateur. En particulier, il contient des données sur chacun des échanges réseaux (ex. : requête HTTP) effectués par le navigateur.
Un fichier .har contient des données en format JSON, qui permet une représentation en arbre des informations (voir Figure 3). Cette structure est composée d’entries (entrées), qui correspondent à des évènements. Sur l’exemple de la Figure 3, l’entrie 0 a un attribut serverIPAddress (adresse IP du serveur) ainsi que des sous-structures request et response qui correspondent à la requête et la réponse de cet échange. Dans request on peut par exemple trouver des attributs comme l’url demandé et son bodySize (taille du contenu de la requête).
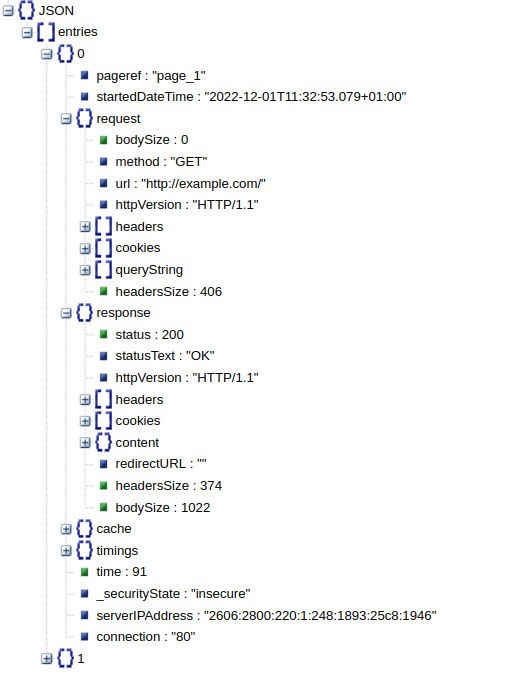
Figure 3 – Exemple de contenu de fichier HAR avec une organisation en arbre via le format JSON.